데이터 모델링
Q. 인터뷰이에게 데이터 모델링이란?
본인에게 데이터 모델링이란, 리터럴리 데이터 베이스를 만드는 단계이다..
Q. 데이터 모델링의 단계를 알려주시라.
데이터 모델링의 단계는 다음과 같다.
- 요구사항 수집 및 분석
- 설계
- 구현
- 운영
- 감시 및 개선
이 중 가장 중요한 단계는 설계라고 단언할 수 있다.
설계: 분석된 요구사항을 기초로 주요 개념과 업무 프로세스 등을 식별하고(개념적 설계), 사용하는
DBMS의 종류에 맞게 변환(논리적 설계)한 후, 데이터베이스 스키마를 도출(물리적 설계)함.
DBMS의 종류에 맞게 변환(논리적 설계)한 후, 데이터베이스 스키마를 도출(물리적 설계)함.
쉽게 말해 개념적 모델링 단계에서 ERD 프로그램으로 개체들 간의 관계를 정의하고 논리적
모델링 단계에서 개체들을 테이블로 만들어 좀 더 실체화(전문 용어로 매핑, 사상)하며, 물리적
단계에서 스키마를 도출하여 구조를 만든다.
모델링 단계에서 개체들을 테이블로 만들어 좀 더 실체화(전문 용어로 매핑, 사상)하며, 물리적
단계에서 스키마를 도출하여 구조를 만든다.
요약 하자면
개념적 단계: 개체 집합 간의 관계 정의.
논리적 단계: 관계를 기반으로 테이블 구조와 PK 정의.
물리적 단계: 각 테이블 내 속성과 속성 타입 정의.
이것이 바로 귀납적 정의인가. 소크라테스는 죽는다.
*개체 집합(entity set): 개체(entity)들을 비슷한 속성의 개체* 타입 기준으로 묶은 것. 이를 다른
말로 ‘테이블’이라 한다.
말로 ‘테이블’이라 한다.
*개체: 속성들의 집합. 테이블에서 하나의 row.
Q. 개념적 모델링 단계에서 그림을 그릴 때, 지켜야 할 규칙이 따로 있는가?
객체: 사각형
관계: 다이아몬드형
속성: 타원형
이 세 가지만 기억 하시라.
Q. 아직까지 본인에게는 ‘개체’라는 개념이 모호하다. 개념적 모델링 단계에서 개체들 간의
관계를 정의한다고 했다. 개체가 정확하게 무엇인가?
관계를 정의한다고 했다. 개체가 정확하게 무엇인가?
두번째 문답에서 언급했 듯, 개체는 테이블에서 하나의 아무개 row라고 할 수 있다. 개체는
여러 속성들로 구성되어 있다. 테이블에서 볼 수 있듯 하나의 row에는 여러 개의 속성이 존재하고
있지 않은가.
여러 속성들로 구성되어 있다. 테이블에서 볼 수 있듯 하나의 row에는 여러 개의 속성이 존재하고
있지 않은가.
개체에서 알아두어야 할 다른 부분이 있다. 바로 ERD 다이어그램을 그릴 때, 우리는 가끔
‘강한 개체’ 타입과 ‘약한 개체’ 타입 개념을 이용한다는 것이다.
‘강한 개체’ 타입과 ‘약한 개체’ 타입 개념을 이용한다는 것이다.
강한 개체(strong entity): 다른 개체의 도움 없이 독자적으로 존재하는 개체
약한 개체(weak entity): 상위 개체에 의존적인 개체. 상위 개체 타입이 반드시 존재해야 함.
약한 개체는 키를 갖지 못하고 식별자(점선)/부분키*를 가짐.
약한 개체는 키를 갖지 못하고 식별자(점선)/부분키*를 가짐.
강한 개체를 그릴 때는 한 줄의 사각형으로, 약한 개체를 그릴 때는 두줄의 사각형으로 표시한다.
*약한 개체는 상위 개체의 PK를 FK를 받아 식별자와 함께 복합키로 사용해야 한다. 식별자는
점선으로 표시한다.
점선으로 표시한다.
예를 들어, 아래 그림을 보시라.
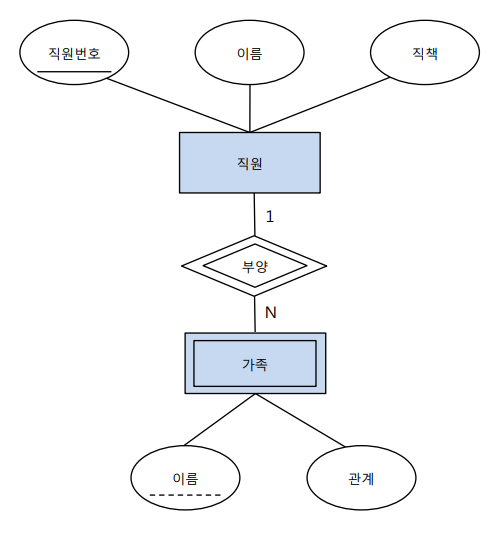
여기서 직원은 강한 객체, 직원번호는 강한 객체의 키, 가족은 약한 객체, 이름은 식별자이다.
가족을 구별할 때는 직원번호+이름으로 복합키를 만들어 구별한다.
가족을 구별할 때는 직원번호+이름으로 복합키를 만들어 구별한다.
Q. 그렇구나. 그렇다면 이제 개체의 하위개념인 ‘속성’에 대해서 다뤄보자. 본인이 알기에 속성은
데이터를 직접 소유하고 있기에 property 이다. 예를 들어 도서가 개체 타입이면, 속성은 도서이
름, 도서번호라 할 수 있다. 속성은 이 개념이 모든 것 아니냐.
데이터를 직접 소유하고 있기에 property 이다. 예를 들어 도서가 개체 타입이면, 속성은 도서이
름, 도서번호라 할 수 있다. 속성은 이 개념이 모든 것 아니냐.
아니다. 공부는 끝이 없다. 차가운 길바닥에서 나뒹굴 거리는 지식은 무한하고 따뜻한 뇌에서 휴식
을 취하고 있는 나의 지식은 유한하다. 나의 머리 크기도 유한하지 않는가.
을 취하고 있는 나의 지식은 유한하다. 나의 머리 크기도 유한하지 않는가.
여튼 인터뷰어는 속성에 대해 잘 알고 있다. 덧붙여 추가할 부분이 있다면,
다중값 속성: 취미(수영, 자전거)와 같이 여러 개의 값을 갖는 속성(이중 타원)
복합 속성: 주소(시,동,번지)와 같이 여러 속성으로 구성된 속성(큰 타원 아래 작은 타원 연결)
Q. 개념적 모델링에서는 용어가 어렵다. 설명해주시라.
차수(degree): 차수란 관계 집합 안에 있는 개체의 수. 예를 들어 2진 관계는 다이아몬드가 하나
사각형이 두 개.
사각형이 두 개.
관계 대응수(cardinality): 두 개체 간의 구체적인 관계. 1:1, 1:N, N:M.
이 용어들은 정보처리기사 필기 시험에 자주 나오니, 명시해 두시라.
Q. 관계 대응수? 응수? 이름 부터가 어렵다.
관계 대응수 1:1, 1:N, M:N에서 1, N, M은 각 개체가 관계에 참여하는 최댓값을 의미한다.

위의 그림에서 볼 수 있듯, 관계 대응수에서 관계 참여 여부에 따라 (최솟값, 최댓값)을 지정할 수
있다. 만약 최솟값이 0이면 관계에 참여하지 않을 수 도 있다는 이야기다.
있다. 만약 최솟값이 0이면 관계에 참여하지 않을 수 도 있다는 이야기다.
그림 6-24의 예시를 보면,
하나의 학과에는 여러 학생들이 들어갈 수 있다.
또, 한명의 학생은 학과에 소속되어 있지 않거나, 여러 개의 학과에 소속되어 있을 수 있다.
하나의 학과에는 여러 학생들이 들어갈 수 있다.
또, 한명의 학생은 학과에 소속되어 있지 않거나, 여러 개의 학과에 소속되어 있을 수 있다.
또 다른 예를 들어(그만 들고 싶다) 보자

(0,*) (1,1) 필수이다.
부서:직원의 관계는 1:N 관계이다.
하나의 부서에는 여러 직원들이 소속되어 있으며,
직원은 적어도 한명은 존재 해야 한다.
부서:직원의 관계는 1:N 관계이다.
하나의 부서에는 여러 직원들이 소속되어 있으며,
직원은 적어도 한명은 존재 해야 한다.
마지막으로 따악 한번만 더 예를 들어 보자면,
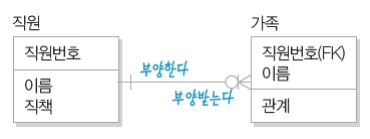
직원과 가족은 식별자 관계이며 (가족의 상위 개체는 직원이다), 직원:가족은 1:N의 관계이다.
직원은 적어도 한 명이 존재해야 하며, 직원은 가족이 없을 수도 /n명일 수동 있다.
직원은 적어도 한 명이 존재해야 하며, 직원은 가족이 없을 수도 /n명일 수동 있다.
Q. 인터뷰이의 이마에 여드름이 났다. 어떻게 생각하는가.
맞다. 요즘 여드름이 다시 나기 시작했다. 본인이 생각하기엔 사춘기가 돌아온 것 같다(웃음).
요즘들어 마음이 자주 심란하다. 나도 나를 모르겠는 순간이 자주 찾아온다. 그래서 단순하게 생
각하려 노력한다. 나름 두 번째 사춘기가 아닌가. 인간은 배울 수 있으니 위대하다고 누가 그랬지
않나(웃음).
요즘들어 마음이 자주 심란하다. 나도 나를 모르겠는 순간이 자주 찾아온다. 그래서 단순하게 생
각하려 노력한다. 나름 두 번째 사춘기가 아닌가. 인간은 배울 수 있으니 위대하다고 누가 그랬지
않나(웃음).
Q. 인터뷰이는 IE 표기법에 대해서 아느냐.
모른다. 실은 지금 배우고 있는 중이다.
IE 표기법은 ER 다이어그램을 더 축약하여 더 쉽게 표현하는 Another 방법이다.
예를 들면

왼쪽의 ER다이어그램을 오른쪽의 IE 표기법으로 달리 표현할 수 있다.
IE 표기법 그림 규칙은 다음과 같다.

까마귀 발꼬락을 주의해서 보길 바란다. 나중에 많이 쓴다.
여기서 아까 관계 대응수의 (최소값, 최댓값)을 적용 해보자면,
‘0, 최소참여가 0일 경우’는 (0, *) 이렇게 표현할 수 있다.
‘1, 최소참여가 1일 경우’는 (1,*)
‘1, 최소참여가 1이고 딱 한 개만 참여해야 하는 경우’는 (1,1) 이다.
앞서 들었던 예시를 가져와 보자,
해석은 다음과 같다.
직원과 가족은 식별자 관계이며 (가족의 상위 개체는 직원이다),
직원:가족의 관계는 1:N의 관계이다.
직원은 가족이 없을 수 도 있는 동시에 n명일 수 있으며,
가족이 존재한다면 적어도 한명에 직원과 연결되어야 한다.
직원:가족의 관계는 1:N의 관계이다.
직원은 가족이 없을 수 도 있는 동시에 n명일 수 있으며,
가족이 존재한다면 적어도 한명에 직원과 연결되어야 한다.
잘 생각 해보아라.
Q. 오늘 따라 캡쳐가 많다. 인터뷰가 귀찮은 것이 아닌가 의구심이 든다.
맞다. 매우 귀찮다.
Q. 오늘 데이터 모델링에 대해 너무 많은 정보를 주셨다. 인터뷰 감사하다.
끝이 아니다. 어디를 가려 하느냐. 못간다. 우리에겐 ‘사상(매핑)’의 개념이 남았다.
지금 까지 개념적 모델링 단계에서는 청사진을 그리는 작업을 배웠다. 논리적 모델링 단계인
여기에서는 청사진을 기반으로 실체화 하는 작업에 대해서 배울 것이다.
여기에서는 청사진을 기반으로 실체화 하는 작업에 대해서 배울 것이다.
그것이 ‘사상(매핑)’ 이다. 다음 그림을 봐라.
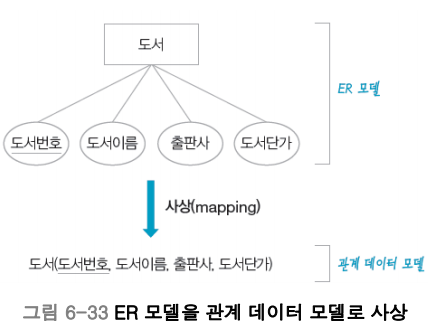
위의 그림과 같이 청사진을 실체로 만드는 작업이다.
Q. 사상 시 지켜야 하는 규칙은 무엇인가?
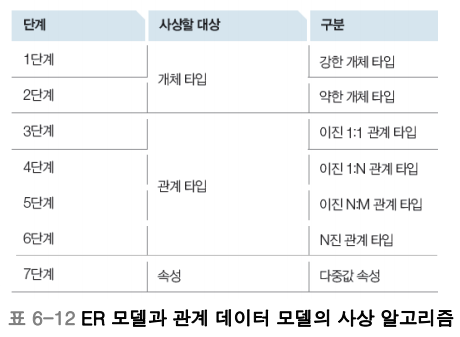
Q. 관계 사상이란 무엇이며 그 방법 은 무엇인가?
관계를 사상하는 것은 테이블(개체 집합)들 간에 그렸던 관계 구조를
직접 실체화 하는 것이다.
관계를 사상하는 방법에는 이진 관계 타입이 있다.
이는 개체에 안의 키들을 활용하는 방법이라 할 수 있다. 이 방법은 관개 대응수(1:1, 1:N, N:M)에
따라 약간 달리 설정해주어야 하는데, 다음 그림을 보겠다.
따라 약간 달리 설정해주어야 하는데, 다음 그림을 보겠다.

[방법1] 오른쪽 개체 타입 E2를 기준으로 관계 R을 표현한다.
E1(KA1, A2)
E2(KA2, A4, KA1)
E1의 KA1를 E2의 FK로 가져오기.
[방법2] 왼쪽 개체 타입 E1을 기준으로 관계 R을 표현한다.
E1(KA1, A2, KA2)
E2(KA2, A4)
E2의 KA2를 E1의 FK로 가져오기.
[방법3] 단일 릴레이션 ER로 모두 통합하여 관계 R을 표현한다.
ER(KA1, A2, KA2, A4)
두 개체 타입을 합치기
[방법4] 개체 타입 E1, E2와 관계 타입 R을 모두 독립된 릴레이션으로 표현한다.
E1(KA1, A2)
R(KA1, KA2)
E2(KA2, A4)
각 키를 FK로 가져와 R 개체 타입 만들어 주기 (N:M 관계에서 사용한다)
앞서, 본인이 관계 대응수에 따라 약간 달리 설정해주어야 한다고 말했다.
예시를 보고 이해해보겠다.

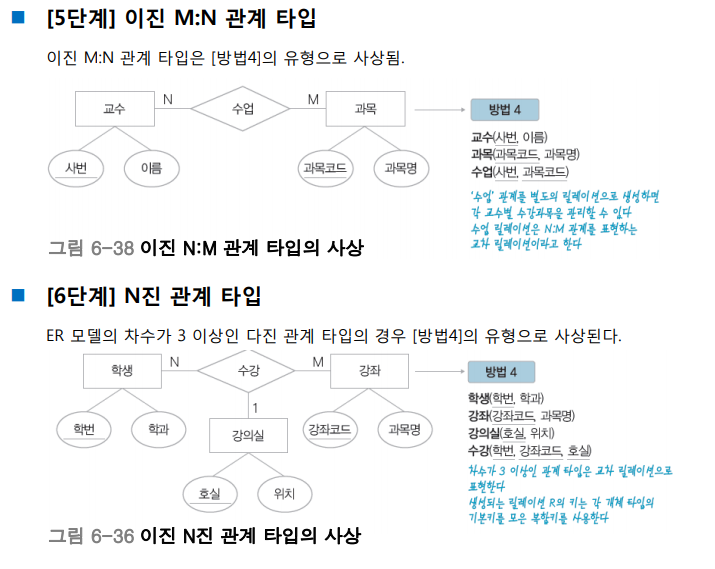
N:M 관계나 N진 관계에서는 무조건 새로운 개체 타입*을 정의해야 한다.
*개체 타입 = 테이블 = 릴레이션
BONUS(+) 다중 값 속성의 사상)
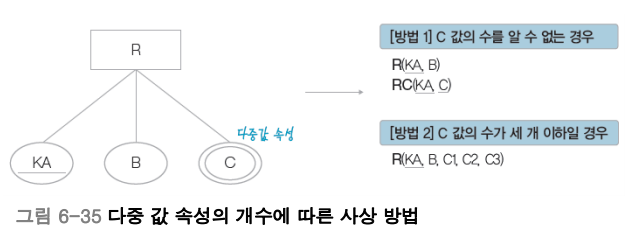
방법[1] 에서 C값의 개수를 알 수 없는 경우는 새로운 별도의 개체 타입을 정의해야 한다.
사실, 방법[2]에서 C값의 수가 N개 여도 처리 가능하다.
예를 들어,
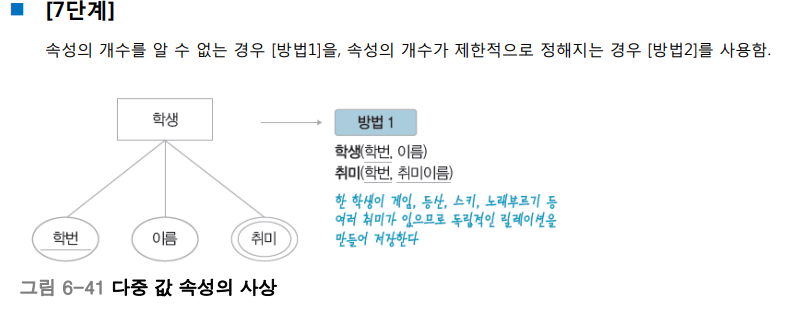
Q. 너무 길다. 데이터 모델링에서 가장 중요한 한 가지를 뽑으라면?
개념적 모델링.
댓글 없음:
댓글 쓰기